klog retrospective
One year into my open-source time tracking project
The storyline behind open-source projects usually goes like this: it all starts with a practical problem that you encounter, which could be solved by technology. You then do some half-hearted research to see how other people might have solved your problem. However, after evaluating a few of the existing solutions, you realise that none of them is convincing. Maybe it’s because they have all but this one particular feature that you need really badly. Or you deem their general quality to be below all reasonable standards. (Yours, namely.) Or you just don’t like them for another arbitrary reason. So why wasting your time any further? You just write your own!
One year ago, I was looking for a better way to track my work times. I already had tried various approaches over the years, from full-featured, automagic web apps, via carefully customised spreadsheets, to old-fashioned pen and paper. (You know, like actual pen and paper.) But they all didn’t click with me.
I actually enjoyed writing into my physical notebook for its simplicity, but having to sum up the total times manually was both tedious and prone to error. The spreadsheet was nice because it displayed data and evaluations right next to each other, but the tabular structure was too rigorous, and the overall experience felt a little generic. The countless online services advertise themselves as clever and convenient, but the downside is that you give away data ownership; besides, I have to say that the complexity of these services somehow feels unreasonably disproportionate compared to how mundane it really is to record some hours here and there.
Time tracking tools are probably high up among the most oftenly solved software problems world-wide. This is an indicator of how different the use-cases and preferences of people are. What I wanted to have is something…
- that would resemble the pen-and-paper simplicity,
- that would store the data in plain old text files,
- and that I could evaluate automatically and flexibly.
The result of these considerations: klog, a file format definition and a matching CLI tool, that I started to work on in December last year. It is meant for people who are a) comfortable with the command line, b) like to organise things in files, and c) value the freedom of open and expressive data formats. That’s a small niche effectively, but klog is still in good company there with tools that share the same philosophy, such as the accounting project “hledger” or the todo manager “todo.txt”.
I don’t want to go into further details here of what klog is and how it works – you find a comprehensive tutorial and more information in the documentation. I rather want to give some insight into how the project evolved throughout this year.
Some facts and numbers
Starting with the initial v1.0 release in February, there were a total of 17 releases2 of the CLI tool so far. The most notable feature additions were:
- Performing manipulations like adding a new time entry to a file
- Setting bookmarks in order to reference often-used files via short aliases
- Providing a JSON interface that allows people to write their own extensions
I’m pretty content with the feature set that klog has reached by now. As mentioned above, I’m aware that it’s not possible to account for each and every use-case, so I didn’t even try to go down that road. It’s also a positive side-effect of the plain-text approach that the natural constraints of the file format help to define (and confine) the function scope of the tool.
Providing programmatic interfaces, which allow users to build custom tooling around klog, turned out to be very fruitful: people have created a VSCode syntax highlighter, rendered data as graphic timelines, or hooked klog into their personal workflows. Apart from that, it’s been valuable that users contributed ideas and shared feedback, which helped to improve the project on all levels.
The CLI tool is implemented in Go and runs on Linux, MacOS and Windows. At the time of this writing, the code base consists of 5½k lines of Go code that are spread across 80 source files. Additionally, there are 3k lines of test code comprising slightly more than 200 unit and integration tests, so I don’t have to be too concerned about regressions.
Freedom for the data
The biggest difference between klog and other (CLI-based) time trackers is that the data format is independent of the tool itself.3 klog’s file format is designed to be human-readable and meaningful on its own, so you actually don’t need any tool at all to review or manipulate your data. I would even argue that it’s possible to understand a .klg file without knowing anything about klog at all. Not only does this give you full ownership of your data, it also has practical advantages when it comes to manipulating files: for example, you don’t have to memorise the exact command to edit a certain time entry, but instead you can just fire up an editor and modify the text directly.
In my mind, the value of open and accessible file formats is generally underrated. It’s usually easier to just think about the features and capabilities of a tool, and to treat the underlying data structures as a mere implementation detail. Besides, it’s also less work to use generic all-purpose storage solutions, compared to defining a custom and domain-specific format.
I personally value the freedom of my data, even at the expense of slight convenience drawbacks. It’s liberating for me to know that I can make sense of my files just by themselves, without having to depend on specific utilities to access their content.
Ease of use
In my experience, a lot of open-source tools suffer from two problems:
- The creators don’t manage to generalise their own use-cases, so the tools remain tailored to very specific workflows or environments.
- The tools are hard to use, so other users struggle to grasp the functional model.
The second aspect is largely about communication, and I invested a good deal of time into addressing that. For example, I wrote up comprehensive documentation, in which I explained what problem klog solves, provided starting points for how to use it, and covered many bits and bobs that people might run into. I didn’t get much feedback about it, but at least I can see that the website is consulted regularly, so it seems to serve its purpose.
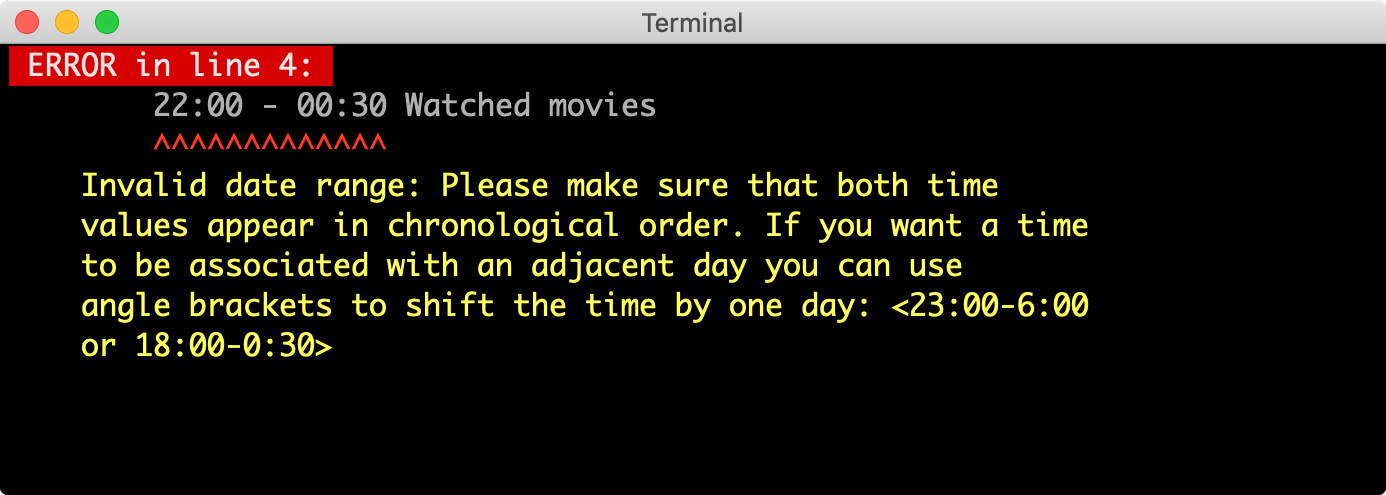
Another example is how the CLI handles error cases: since users are supposed to manipulate their files by hand, it is especially important to give precise details where a problem occurred and how it might be resolved.
Windows shenanigans
I initially didn’t provide a native binary for Windows. This was not so much because I expected Windows support to be overly complicated, but I rather thought that the demand for terminal-based productivity tools wasn’t all that high on Windows in general. Both judgements turned out to be wrong.
Cross-compilation itself is a no-brainer in Go, but compiling alone is not even half the story, unfortunately: line endings, file path conventions, file attributes, terminal formatting, symlinks – even for a relatively small application like klog, there was a considerable number of things to account for. All in all, it took much more effort to sort them out than I had anticipated. (I have also to admit, though, that I don’t use Windows myself and don’t know much about it in general.) Nowadays, the usage of klog seems to be roughly even between all three platforms, so in the end it proved to be a worthwhile time investment.
-
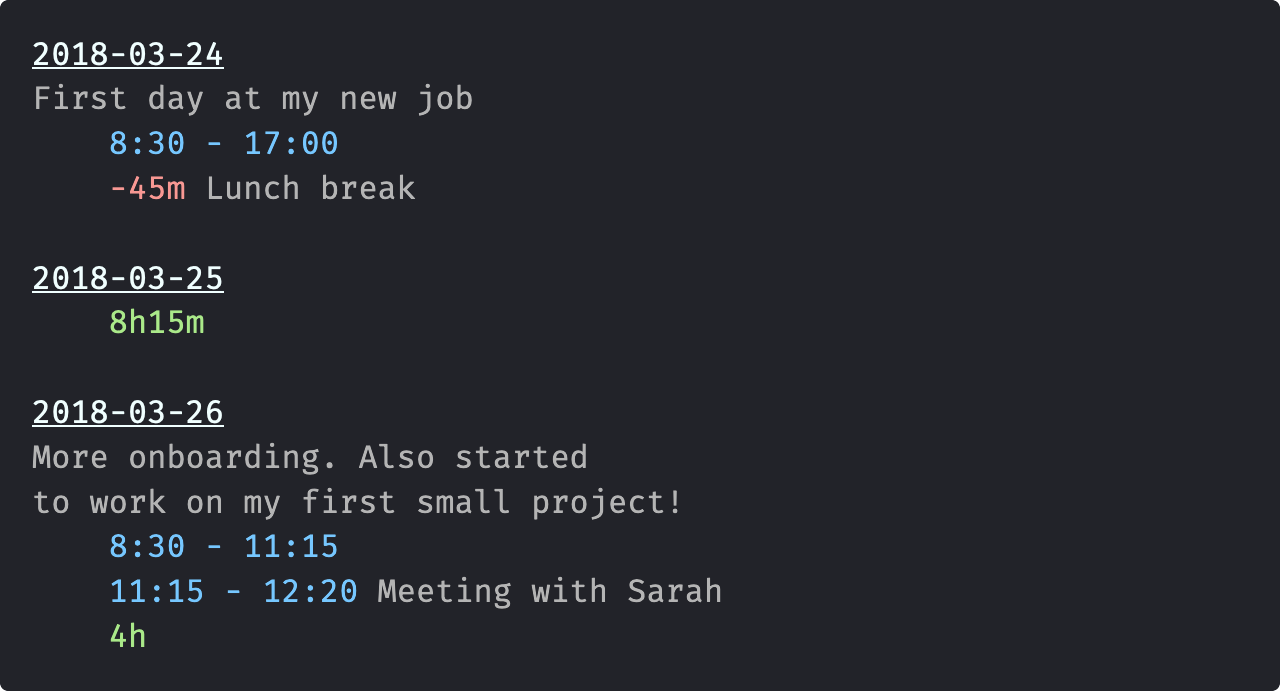
This is an example of what a
.klgfile looks like. The highlighted syntax is costmetic and helps to emphasise the semantics of the text fragments. ↩︎ -
See klog changelog to get an overview of all version updates. ↩︎
-
The klog file format is defined in a formal specification document. ↩︎
-
A sample error message in case there is a syntactical or logical problem in the file. ↩︎